ML2022-Lecture1-Notes
What is Machine Learning?
Machine Learning ≈ Looking for Function
Different types
- Regression(回归): 输出要预测的数值
- Classification(分类): 输出给定的options中的某一个
- Structured Learing: 创造有结构的物件(作图,写文章)
从最基本的Linear Model开始
例: 预测youtube频道第二天播放量

构建模型
基本术语:
- model: 带有未知参数的函数, 这里就是
- feature: , 已知的数据
- weight, bias: 分别是和
定义损失函数
一般可以表示为:
其中e代表每组数据预测值跟真实值的误差, e可以有不同的计算方法, 如MAE/MSE等。
Error Surface
测试不同的参数后画出的Loss的等高线图
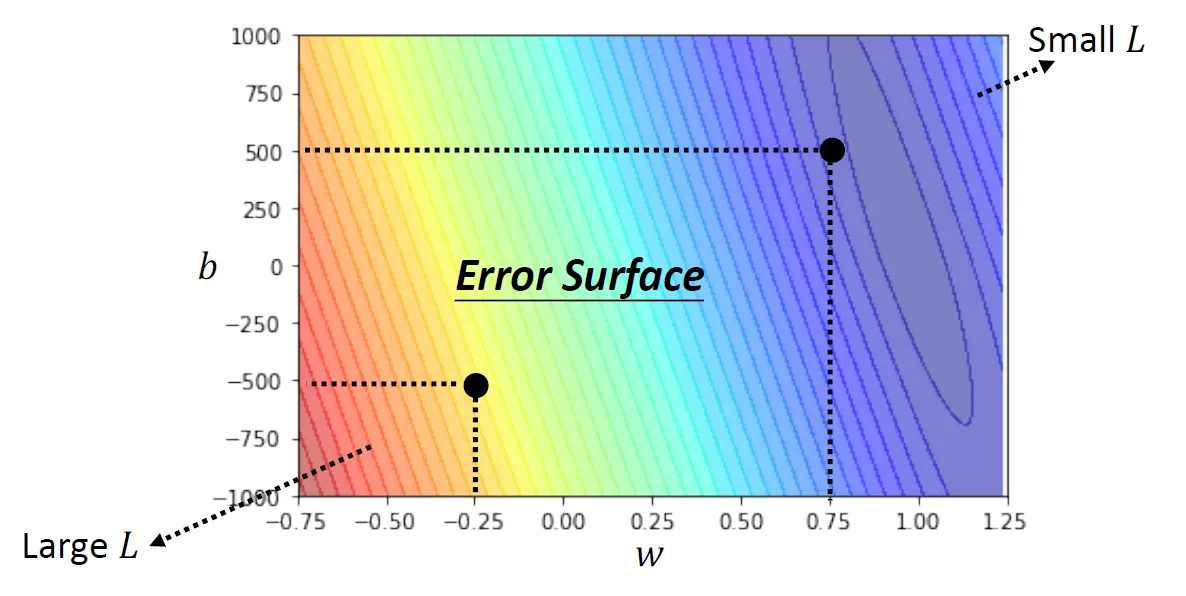
最优化(optimization)
梯度下降(gradient descent)
- 随机挑选初始值
- 更新参数:
- 迭代
其中就是学习率(learning rate), 一般要手动设定。
我们把ML中需要手动设定的参数称为hyperparameter
问题: 局部最优解(local minima) (?)
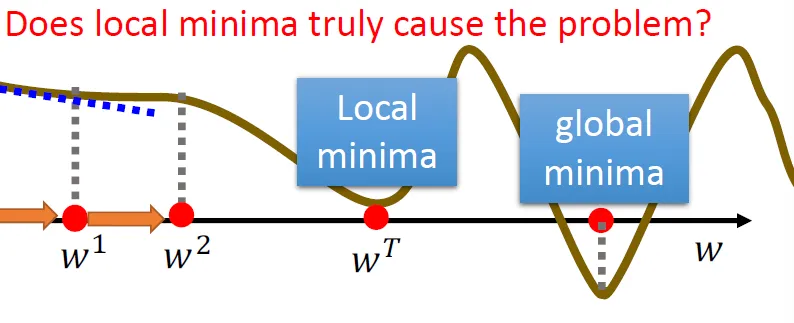
并非真正的难题
更加复杂的model
关于激活函数
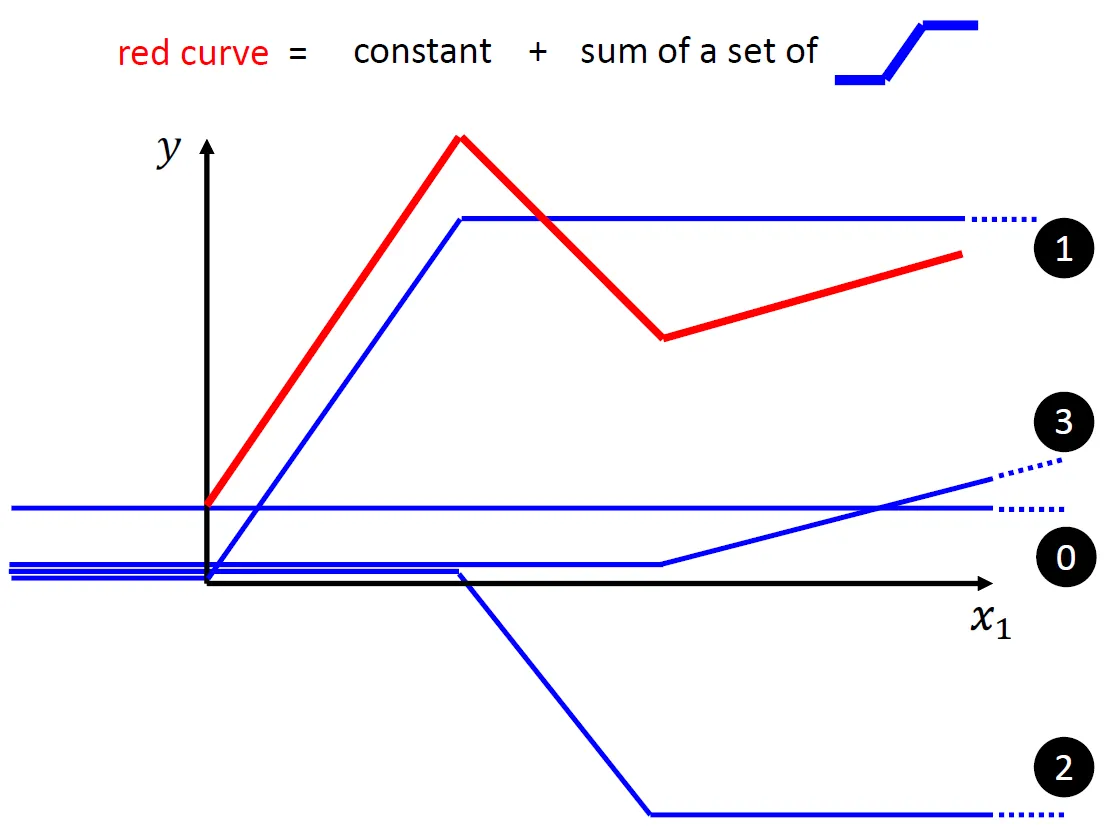
大部分复杂的函数图像理论上都可以使用大量的蓝色折线图叠加来表达
但是我们又该怎么表示这个「蓝色的折线图」呢?
🤓☝️我们有sigmoid函数
而实际上这条「蓝色的折线图」就通常被称为「Hard Sigmoid」
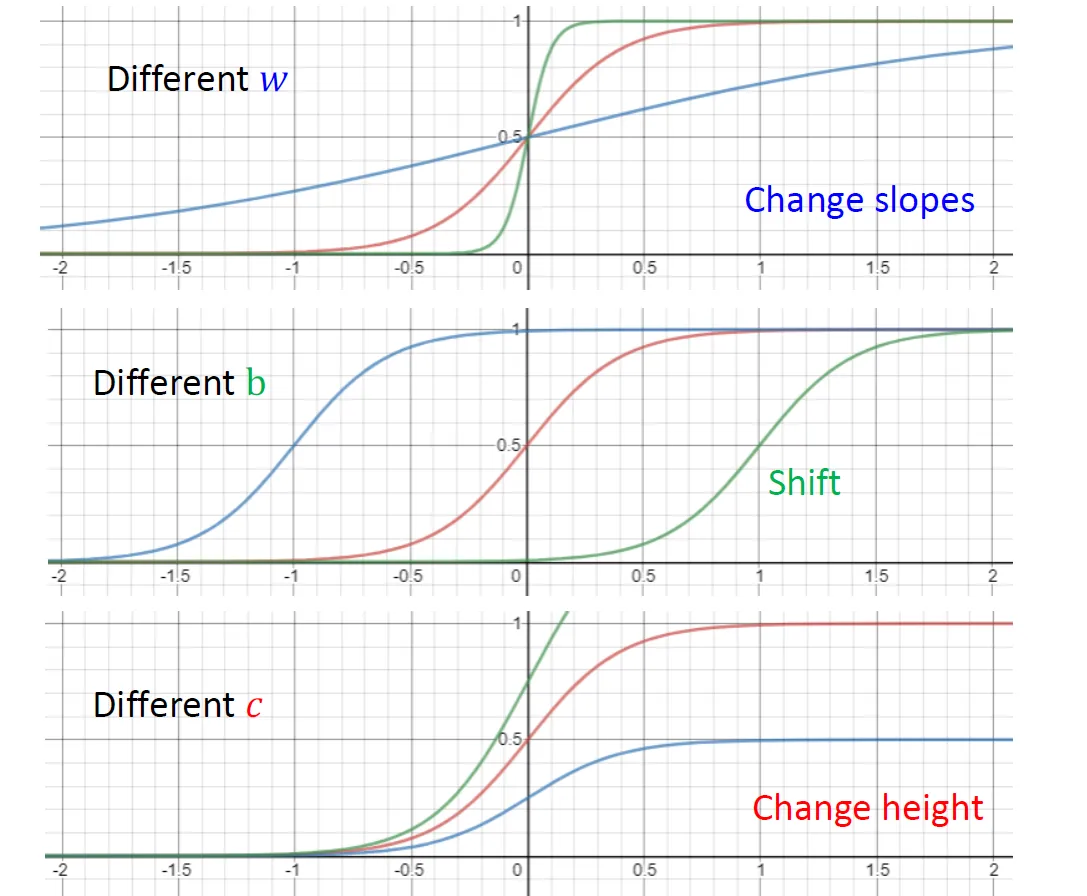
改变参数对图像的影响:
除了sigmoid函数, 我们还可以用ReLU函数:
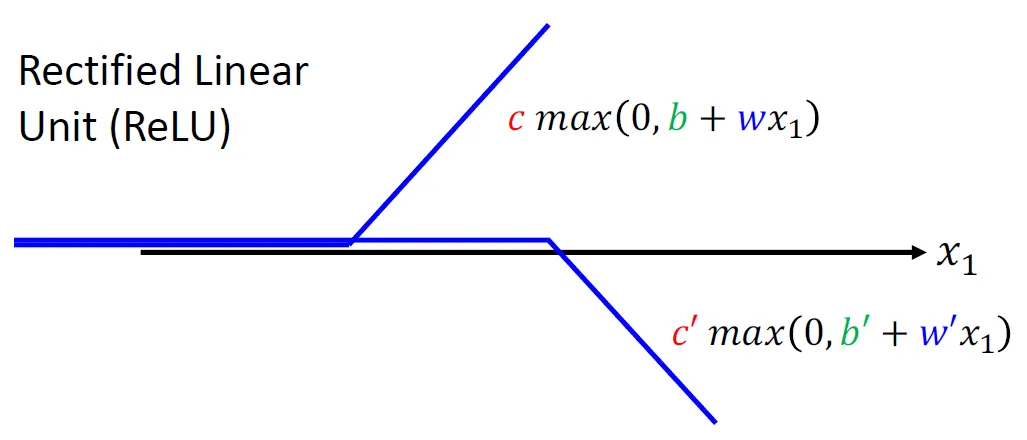
那么对于这样的sigmoid函数或者ReLU函数或者其他的函数, 我们就将其称为激活函数。
以下我们基于使用sigmoid函数的情况。
Neural Network
对于一组feature, 我们有:
如果我们想要同时考虑 组feature:
我们引入线性代数中向量与矩阵的概念来简便地表示y:
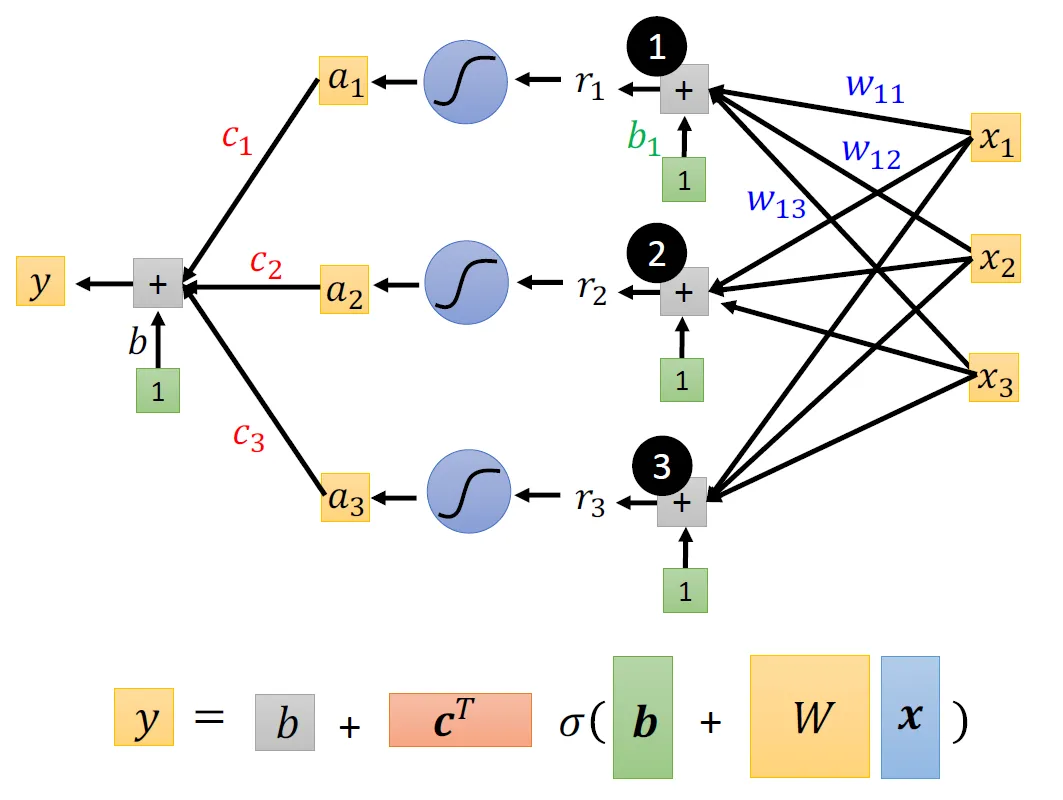
然后我们把继续作为新的, 引入更多未知的参数来让函数更复杂:
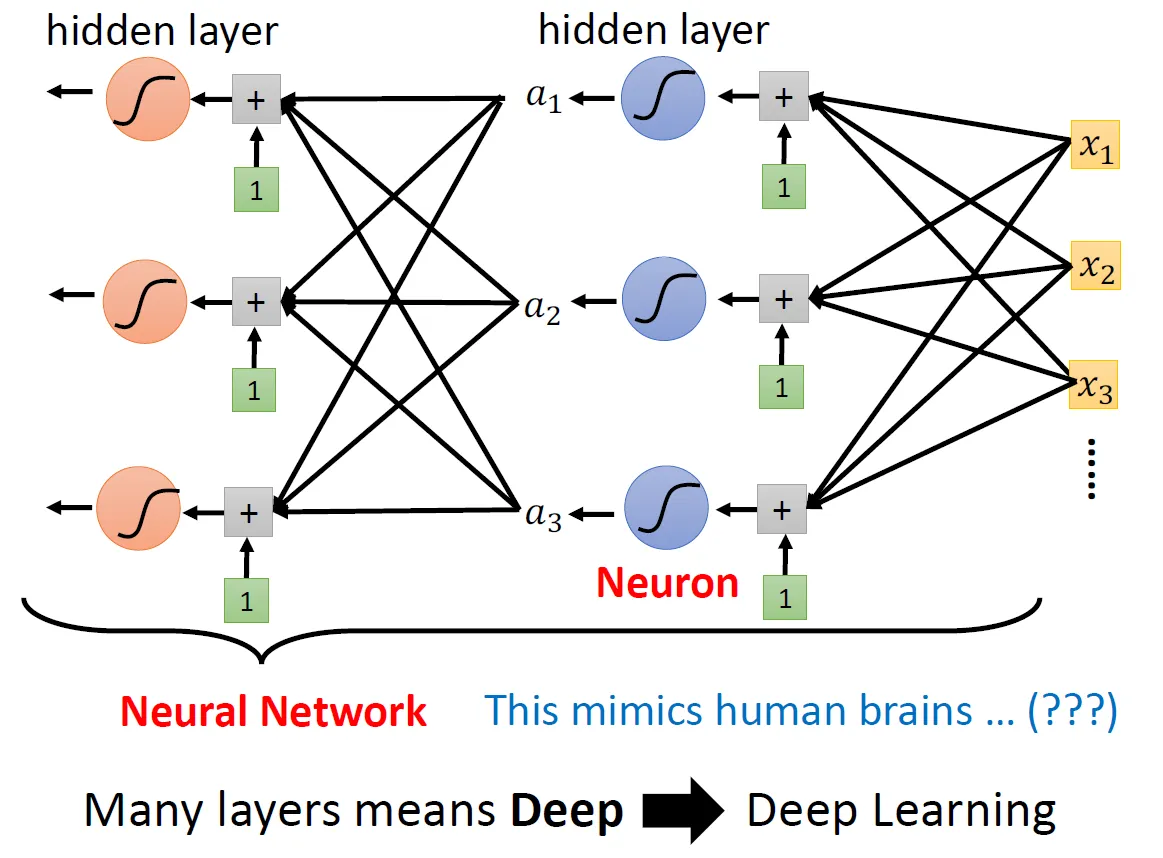
然后我们就有了Neural Network (:
-
为什么不在一层上增加更多的节点让网络「变宽」而是要多做几层让网络「变深」?
以后再讲(((
(后续可能会补链接) -
为什么不能一直增加深度?
容易带来过拟合的问题: 在训练集上表现变好但在未知数据上表现变差